Petar Petrović II
Obećava
- Poruka
- 89
2. Tema: Metajezik rešenja
> Može li se filozofski problem rešiti algoritmom?
Ako zamislimo metajezik kao alat, on ne opisuje samo pojmove nego i rešenja. Zamišljam ga kao most između filozofije i računara — mesto gde misao postaje kod.
Da li mislite da bi ovakav pristup mogao da reši stare filozofske dileme ili bi ih samo pretvorio u tehničke zadatke?
> Može li se filozofski problem rešiti algoritmom?
Ako zamislimo metajezik kao alat, on ne opisuje samo pojmove nego i rešenja. Zamišljam ga kao most između filozofije i računara — mesto gde misao postaje kod.
Da li mislite da bi ovakav pristup mogao da reši stare filozofske dileme ili bi ih samo pretvorio u tehničke zadatke?

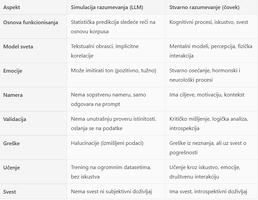
 LLM jeste otišao dalje od samog „pričanja“ i može da napravi programe, dizajn i čitave projekte. Ali to radi tako što predviđa sledeće reči u nizu na osnovu ogromne baze podataka — dakle, projekat je rezultat predikcije statističkog modela, a ne stvarnog razumevanja.
LLM jeste otišao dalje od samog „pričanja“ i može da napravi programe, dizajn i čitave projekte. Ali to radi tako što predviđa sledeće reči u nizu na osnovu ogromne baze podataka — dakle, projekat je rezultat predikcije statističkog modela, a ne stvarnog razumevanja.